
“Cloud computing” is one of the most overloaded terms in the history of information technology. Yes, there is the NIST Definition of Cloud Computing [1] that many will point to, but the sheer number of adaptations of models for “enabling ubiquitous, convenient, on-demand” access to computing resources knows no limit.
When we narrow the aperture a bit, even to broad horizontal use cases such as supercomputing and HPC, things become a bit clearer. Partly, this has to do with the relatively late adoption of cloud-like concepts in this space. I remember having conversations in 2013 and 2014 with “birds of a feather” who simply laughed at the idea of doing “proper” HPC in the cloud. Cloud generally meant cheap storage and compute – the antithesis of supercomputing. Obviously, things are different today, but it’s not simply because of the technological advances in the space. The industry managed to take a step back from terminology and purity and think about actual unsolved problems, and how new paradigms could help if adapted the right way.
For the Atos Nimbix Supercomputing Suite [2], we applied this logic to three major and very different types of issues and found that a common technology thread worked across the board. In fact, we also learned that while the models are different, organizations often benefit from more than one, and in some cases all three – whether immediately or over time.
Elastic Supercomputing
The most “cloud-like” of the three models, Elastic [3] caters to researchers and engineers who are looking for on-demand access to advanced computing and applications without complex procurement, configuration, build-out, and tuning processes. They simply log into a web portal, choose a workflow and a dataset, and run it. Most elastic users can get started in minutes. This is software-as-a-service (SaaS) for HPC.
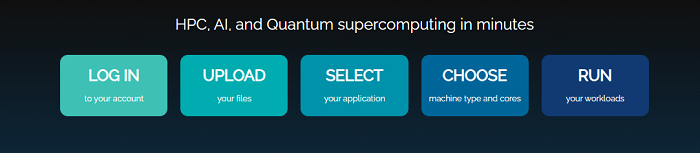
Over the years, we found the most obvious inflection point to be when workstations are simply not enough to run solvers at the required scale and performance. Organizations that don’t already have clusters often find it quite difficult and cost-prohibitive to level up to large-scale HPC. It means buying equipment, leasing datacenter space, hiring experts, and spending months putting everything together. There are plenty of consultants and services out there to help, but obviously at a commensurate cost. For the engineers needing to get work done faster, the appeal of simply running the same application they already do on their workstation but at eight or sixteen times the scale for a fraction of the price is hard to ignore. There are plenty of cost models that would argue otherwise, but all require major investment up front in both time and resource, and none solve the problem “right now” like SaaS does.
What’s more, the Elastic model even helps those organizations that already have HPC in-house. Whether it’s expanding access for users who are not as skilled in writing traditional job scheduler scripts (but are otherwise brilliant in their respective science/engineering domain), or quickly augmenting capacity during peak periods without lengthy upfront setup or commitment, HPC SaaS adds practical options at a fair price. The Nimbix Elastic offering even supports federated multi-zone usage to respect data sovereignty and governance across geographies. In short, it can help any organization, even a multi-national one, get more work done quickly and with virtually no up-front effort.
Dedicated Supercomputing
Physical, on-premises (or even privately hosted) infrastructure is generally at odds with the concepts of cloud computing, but its procurement and consumption models need not be. It’s true that many organizations have specific requirements that only dedicated clusters can meet. Cloud enthusiasts will argue that the largest, most powerful compute clusters in the world are already available on demand from various “hyperscale” companies, but particularly with HPC, real-world offerings may still not meet all customer requirements. And of course, there is cost – full-time use of systems gets expensive when paying on-demand prices.
But customers needing control of their own infrastructure still face two problems that cloud-like solutions, whether the technological kind or the contractual kind, can easily address. First, there’s the need for OPEX-style financing, particularly of what is naturally a depreciating asset. Additionally, considering most systems may not be utilized to their full capabilities at all times, tying up capital is a difficult proposition to make. Paying for hardware “as you go”, as if it were infrastructure-as-a-service, can be attractive, especially if you factor in growth and elasticity needs. When customers need more hardware, they simply pay a larger monthly bill and have immediate access to it rather than entering an entire new procurement cycle to purchase all of it at once. This is not unlike leasing, except with more elasticity and flexibility.
The second problem is about usability and access – again, similar in scope to what drives some customers to the SaaS model of Nimbix Elastic. Continuing to buy systems that only experts in both domain science and information technology can use limits innovation, particularly as demand for talent becomes more and more specialized. Why preclude the best engineers and researchers in their respective fields simply because they are not highly skilled at interacting with scheduler software developed decades ago for batch computing purposes? It doesn’t make a lot of sense. Democratization of HPC helps everyone, regardless of how compute capacity is delivered.
Nimbix Dedicated solves both problems, introducing an on-demand financial model for procuring equipment, and seamlessly enabling the world’s leading HPC-as-a-service application delivery platform, JARVICETM XE [4]. What’s more, bursting to other infrastructure, including public clouds, is a simple matter of pointing and clicking in the modern web-based user interface. While this may not be an immediate need for some organizations, it’s in almost everyone’s plans for “next generation” supercomputing. Nimbix Dedicated enables it all right now.
Federated Supercomputing
The age-old problem of what to do with spare computing capacity is no different in HPC as it’s been for decades in the mainframe world. Customers pay for lots of compute, and they don’t always use it. Rather than relying on a vendor to help drive utilization, why not offer this capacity to the market in exchange for fees to help fund its ongoing operation and financing?
Nimbix Federated [5] solves this in one of two ways. The first is with an Atos-managed global control plane that any organization can join simply by deploying software components and connecting to it – in essence becoming service providers but with minimal operational overhead. These newly minted providers decide what resources to make available, at what cost, and to what customer or customers. Atos does the rest, operating the JARVICE XE platform to securely manage all the infrastructure, including billing and accounting. When customers use a provider’s cycles, that provider gets paid.
The second is with a “private” federation, where a group of providers join forces to exchange capabilities, capacity, and even encourage collaboration. Rather than attaching to a public control plane, they deploy and operate their own. Atos can manage it for them as well if they like. This way, a related group of institutions can make their own rules, ensuring policies and governance are always met to their precise standards (e.g., when dealing with sensitive data such as healthcare, energy, and defense). But rather than each provider managing all users and settings for all “client” organizations, they simply connect to the control plane and let it handle it for them. Once again, the JARVICE XE platform facilitates all this.
When three very different (but often converging) paradigms rely on similar technology, everyone wins. Transitioning between delivery models becomes basically transparent to end users, ensuring innovation above all else continues at the blinding pace the world needs. This is, after all, supercomputing’s raison d’etre.
Atos will have more exciting HPC announcements in the coming months and we are excited to see everyone in person this year at our booth at SC’22 in Dallas, Texas in November.
About the Author
 Leo Reiter, CTO and Technical Director of the Atos HPC Cloud Competency Center
Leo Reiter, CTO and Technical Director of the Atos HPC Cloud Competency Center
[1] https://csrc.nist.gov/publications/detail/sp/800-145/final

